Related Topics:
Nvidia Server Power Roadmap-
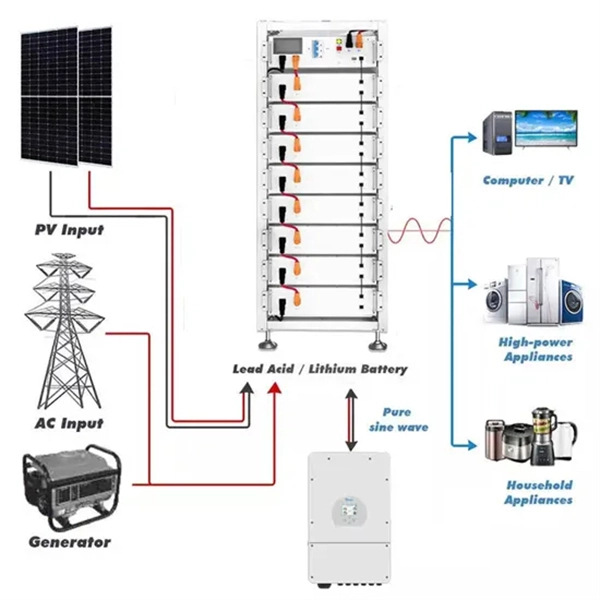
Are the different components of an AI server a large proportion of its overall performance
While traditional servers rely mostly on CPUs, AI servers lean heavily on graphics processing units (GPUs) and similar AI accelerators that are purpose-built to handle modern AI models. That's the job of an AI server—a custom-built system that keeps AI applications fast, scalable, and efficient. These servers require a combination of high-performance hardware components to process large datasets. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Key hardware components include a multi-GPU motherboard, high-performance CPU, at least 96GB RAM, effective cooling, a robust. From training complex deep learning models to performing real-time inference, the underlying server infrastructure plays a pivotal role in determining the speed, efficiency, and scalability of AI operations. A critical decision for anyone embarking on AI development or deployment is selecting the.
[PDF Version]
-

How many watts does an AI server consume
A fully populated AI server rack with eight high-performance GPUs, dual CPUs, networking cards, and storage can easily consume 12-15 kilowatts of continuous power. GPUs for AI ran at 400 watts until 2022, while 2023 state-of-the-art GPUs for generative AI run at 700 watts, and 2024 next-generation chips are expected to run at 1,200 watts. The average power density is anticipated to increase from 36 kilowatts per server rack in 2023 to 50 kilowatts per rack by. The average AI rack costs $3. Sources: Uptime Institute 2020/2024 Surveys, Ramboll US data centers consumed 176 TWh in 2023, representing 4. By 2024, that rose to approximately 183. In 2023, U. This comprehensive guide explores exactly how much electricity data centers use, what drives their enormous energy appetite, and what the future holds as. Global electricity consumption from data centers reached approximately 415 terawatt-hours (TWh) in 2024, representing about 1. This figure is projected to more than double by 2030, reaching between 945 TWh and 1,050 TWh.
[PDF Version]
-

Huawei AI Server Liquid Cooling
Huawei developed a full liquid cooling solution, reducing the power consumption by 96% and cutting the PUE from 2. This increase in power density has posed an unprecedented challenge to conventional cooling systems. To address this challenge, Huawei. Advanced AI chips are generating more heat in data centers, necessitating improved cooling solutions. Proposed techniques include circulating water through cold plates, circulating boiling liquid through cold plates. Liquid cooling is essential for AI-driven data centres, efficiently managing the extreme heat generated by high-density AI server racks. It offers up to 15% better energy efficiency and reduces cooling costs compared to traditional air-cooling systems The technology also enables higher server. This AI revolution is built on incredibly powerful computer chips. But there's a catch, a hot one. These chips, especially the GPUs that are the workhorses of AI, are generating a staggering amount of heat.
[PDF Version]
-

Current Status of AI Server Development
Dell, HPE, Lenovo, and Supermicro are riding record AI server demand, but winning enterprise customers requires more than just Nvidia chips. With GPUs standardized around Nvidia, vendors compete on AIOps, liquid cooling, and deployment services as enterprises ramp up inference in 2026. A comprehensive report by Global Market Insights Inc. The market is expected to grow from USD 167. 88 billion in 2024, at a CAGR of 34. This surge is driven by rising demand for AI applications, advancements in AI technology, cloud and edge computing expansion, and big data analytics. The AI server market is projected to reach US$245 billion in 2025 and is expected to grow to US$523 billion by 2030, driven by rising demand for Generative AI (Gen AI) tools like ChatGPT, Perplexity, and Claude, ABI Research said in a report. Enterprises increasingly deploy AI models in-house.
[PDF Version]
-

P40 multi-GPU AI server
We've built a homeserver for AI experiments, featuring 96 GB of VRAM and 448 GB of RAM, with an AMD EPYC 7551P processor. We'll be testing our Tesla P40 GPUs on various LLMs and CNNs to explore their performance capabilities. We'll also share our approach to cooling these GPUs. more Audio tracks. Tesla P40 24GB for possible local AI server build. 0 16x lanes, 4GB decoding, to locally host a 8bit 6B parameter AI chatbot as a personal project. Would. This guide details the configuration steps required to properly set up multiple Tesla P40 GPUs in passthrough mode for Ollama on an Ubuntu 22. 04 VM running on a Proxmox host. Edit your VM configuration file (/etc/pve/qemu-server/YOUR_VM_ID. It runs 30B+ models that gaming GPUs under $200 can't touch. The catch: no display output, no fans, no native FP16, and you'll need a cooling mod. Pre-installed NVIDIA drivers, Linux/Windows support, and flexible CPU–Memory–GPU combinations make it ideal for AI training, inference, rendering, and scientific computing. Equipped with a substantial 24 GB of GDDR5 VRAM, this GPU is an intriguing option for those looking to run local text generation models.
[PDF Version]
-

The server belongs to AI
AI servers are high-performance computing systems designed to process complex artificial intelligence workloads, including large-scale model training and real-time inference. Some of these operations involve deep learning, image recognition, and natural language processing. They provide the hardware environment —. Unlike traditional servers designed for general-purpose computing tasks such as hosting websites or managing databases, AI servers are specialised systems engineered to handle the specific computational demands of AI workloads. Deep learning digs through massive data sets to find meaning the way a.
[PDF Version]
-

Multi-channel AI Server
In this guide, you'll learn how to architect a Multi-Channel Processing (MCP) server using FastAPI and LangChain. This setup is ideal for projects involving LLMs and AI agents, where performance, modularity, and extensibility matter. 🚀 Why FastAPI + LangChain?OpenClaw is a self-hosted gateway that connects WhatsApp, Telegram, Discord, and iMessage to AI coding agents. You run one Gateway process on your machine, and it becomes the bridge between your messaging apps and an AI assistant you control. OpenClaw installed and running. A configuration file (usually. OpenClaw's multi-agent routing lets you run a whole team of specialized AI agents — each with their own personality, memory, and skills — all from a single server. This. Our stack prioritizes performance, reliability, and scalability, serving as the foundation for teams shipping production-grade autonomous systems.
[PDF Version]