DGX Spark: The Sovereign AI Stack
DGX Spark: The Sovereign AI Stack — Dual-Model Architecture for Local Inference Greetings to the community, I am pleased to share my
Get QuoteIn this guide, you'll learn how to load test vLLM inference servers using LoadForge and Locust. We'll cover how vLLM behaves under load, how to write practical Locust scripts against real vL...
HOME / AI Inference Server Concurrency Test - ABC Stimulo Photonics
AI Inference Server Concurrency Test - ABC Stimulo Photonics [PDF]

DGX Spark: The Sovereign AI Stack — Dual-Model Architecture for Local Inference Greetings to the community, I am pleased to share my
Get Quote
A working list of every major AI API that offers free credits or a free tier in 2026. Token limits, rate caps, and what you can actually build.
Get Quote
How to design a latency-testing protocol that exposes batch, concurrency, and tail-percentile behavior under realistic AI inference load.
Get Quote
This article walks you through the essential process of load testing your Mosaic AI Model Serving endpoints to ensure they can handle production workloads effectively.
Get Quote
OpenRouter: Access to hundreds of models including free tiers from various providers DeepSeek: Direct API access to DeepSeek chat and reasoner models LM Studio: Fully local
Get Quote
NVIDIA DGX Spark enables efficient execution of autonomous AI agent workflows, supporting large context windows, high concurrency, and
Get Quote
vLLM vs Ollama: Which Local AI Server to Run in 2026 Stop compromising on inference latency. While Ollama masters desktop simplicity, vLLM''s PagedAttention engine unlocks high
Get Quote
MacBook Neo''s A18 Pro delivers 35 TOPS at $599. But 8GB RAM and 60 GB/s bandwidth means your AI app still needs a cloud API. Here''s the data.
Get Quote
Load testing and performance benchmarking are two distinct approaches to evaluating the deployment of an LLM. Load testing focuses on
Get Quote
For AI engineering teams, this eliminates multi-node distributed network headaches and consolidates infrastructure management. Below is a detailed look at how the tests were conducted and the
Get Quote
Test how your server handles thousands of concurrent users with a controlled ramp-up to avoid overwhelming connection establishment. A longer ramp-up gives the server time to allocate
Get Quote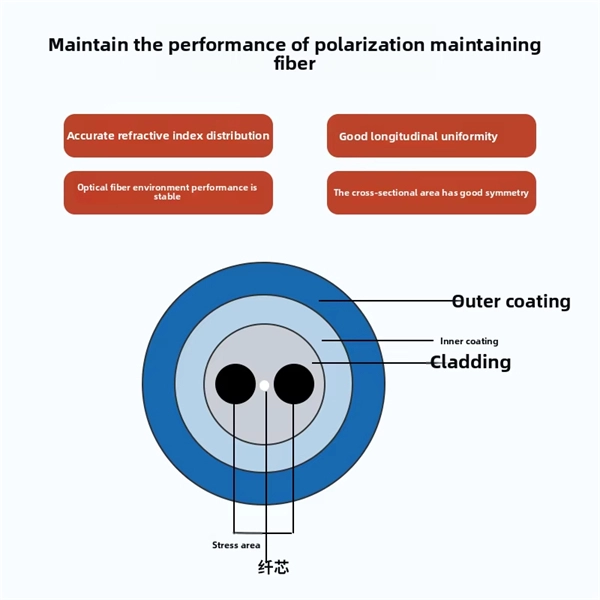
Connect with builders who understand your journey. Share solutions, influence AWS product development, and access useful content that accelerates your growth.
Get Quote
Libraries and server to build AI applications. Adapters to various native bindings allowing local inference. Integrate it with your application, or use as a microservice.
Get Quote
I''ve also recently shifted from Ollama to vLLM, as things broke when I tried to productionize my AI service, and my use case had higher concurrency, which Ollama wasn''t
Get Quote
Huawei staff at the exhibition said supporting FP16, FP8 and FP4 allows servers integrating Atlas 350 to run larger models with lower inference latency. In measured tests for internet
Get Quote
Review the inference speed, latency, and throughput in several scenarios when one or more concurrent users call large language models hosted on dedicated AI clusters in OCI Generative
Get Quote
One of the biggest misconceptions in #enterprise_AI right now is that you need radically different infrastructure for #inference_workloads. Hands on testing of he Dell Technologies
Get Quote
Penguin Solutions'' OriginAI portfolio addresses the need for +GPU memory to solve context size/concurrency & meet low latency demands of AI inference.
Get Quote
This leads to the marginal bump in the Time to First Token (TTFT). Benchmarking Multi-User Concurrency (24GB GPU Tier) If you plan to expose
Get Quote
This article covers: the five-step stress testing protocol, defining baseline metrics before testing, building realistic load profiles, running trials on actual platform hardware, interpreting key
Get Quote
In this guide, you''ll learn how to load test vLLM inference servers using LoadForge and Locust. We''ll cover how vLLM behaves under load, how to write practical Locust scripts against real
Get Quote
Responsibilities Deploy and run large language models directly on our server infrastructure without LM Studio Configure GPU inference serving for Gemma 4 26B (or similar open-source LLMs) Integrate
Get Quote
In this post, I''ll walk you through how I benchmarked inference performance using vLLM, a fast and memory-efficient LLM serving engine.
Get Quote
For broader GPU selection guidance, see the Best GPU for AI inference 2026 guide. Real-Time Object Detection (YOLOv11) Object detection is the one workload where smaller GPUs
Get Quote
Need help learning Computer Vision, Deep Learning, and OpenCV? Let me guide you. Whether you''re brand new to the world of computer vision and deep learning
Get Quote
Raw throughput is only half the inference-engine decision. This guide teaches PagedAttention with worked memory math, analyzes an H100 benchmark snapshot, then explains
Get Quote
Agentic AI doesn''t just move AI forward, it flips the infrastructure built for traditional inference on its head. Agentic AI, systems that reason, plan, use tools, and execute multistep tasks
Get Quote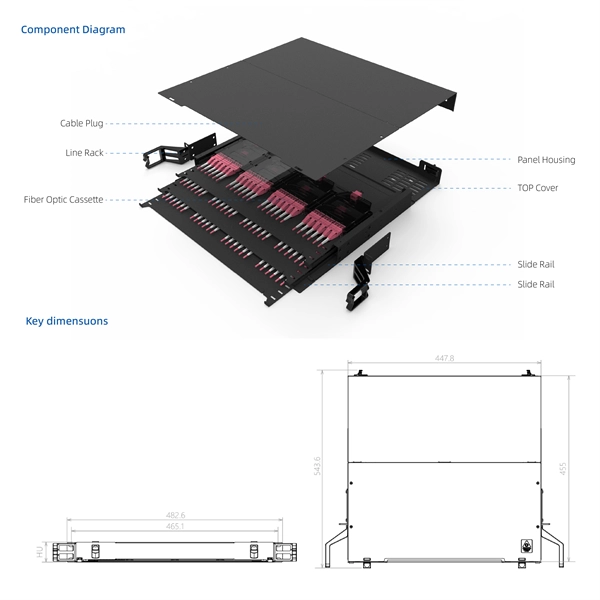
Learn how to combine KServe and llm-d to optimize generative AI inference, improve performance, and reduce infrastructure costs. This article demonstrates the integration architecture
Get Quote
In load testing, as well as real-world systems, the relationship between client concurrency, server concurrency, and latency is dynamic and interdependent. Let''s see this relationship with a
Get Quote
We benchmarked the latest NVIDIA GPUs, including the NVIDIA (H100, H200, and B200) and AMD (MI300X), for concurrency scaling analysis.
Get Quote